En 2001, David. A. King, spécialiste des mathématiques dans le monde arabe du Moyen Âge, se permet une petite sortie de son domaine d’expertise principal pour publier The ciphers of the monks – A forgotten number-notation of the Middle Ages. Dans cet ouvrage il fait état de sa recherche concernant un système de notation numérique utilisé notamment par des moines à partir XIIIe siècle et possiblement jusqu’au XVIIIe siècle pour la notation de quantité de vin en barrique. Peu documenté et étudié avant lui, ce système a pour particularité de pouvoir écrire les nombre de 1 à 9999 en un seul signe composite.
Pourquoi ce système ?
D’après les travaux de King, ce système (comprenant de nombreuses variantes) a été utilisé pour la création d’index, la pagination ou la notation des années sur des manuscrits et même sur un astrolabe du XIVe siècle. Cette notation serait inspirée par un système sténographique grec importé en Angleterre par le moine John de Basingstoke. La méthode se serait ensuite propagé en actuelle Belgique et France et plus largement en Europe puisqu’il fait état de son utilisation dans des ouvrages en Espagne et en Italie. Il faut prendre en considération qu’à l’époque la notation en chiffres indo-arabes n’était pas totalement répandue, et que la notation romaine était encore très présente. S’agissant de notations de nombres sans besoin de calcul, ce système pouvait être considéré comme plus performant que la notation romaine du type « MCMXCIII » (1993), qui, je pense pouvoir le dire, n’est pas des plus aisée à interpréter de par son mode de fonctionnement. Le système, à priori très peu utilisé (le corpus est en tout cas très limité) a fini par être abandonné au profit de la notation indo-arabe que nous connaissons et utilisons aujourd’hui couramment.
Fonctionnement
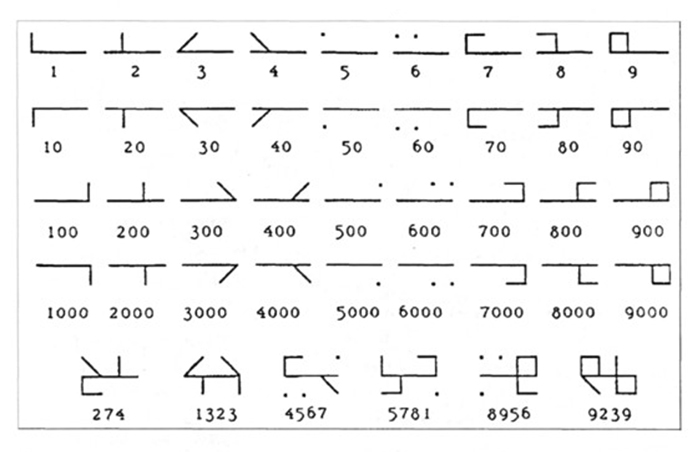
Ce « code » est fondé sur une construction extrêmement simple : un fût sert d’axe principal, il a en soit une valeur numérique nulle, soit zéro. Il sert surtout de « point d’appui ». Quatre zones sont délimitées de part et d’autre de cet axe, chaque zone correspondant au milliers, centaines, dizaines et unités. Un signe (à base de barres la plupart du temps) codant pour une valeur numérique de 1 à 9 peut être adjoint à une des zones, signifiant le nombre soit de milliers, soit de centaines, de dizaines, ou d’unités selon sont positionnement. La valeur nulle étant simplement signifiée par l’absence d’élément dans la zone correspondante. Le signe de base est toujours le même, mais il peut être inversé horizontalement et/ou verticalement selon la zone qu’il occupe. De fait, un nombre tel que 9999 aura une construction symétrique étant donné qu’il y a [9] quantités dans chacune des catégories : [9] milliers, [9] centaines, etc.
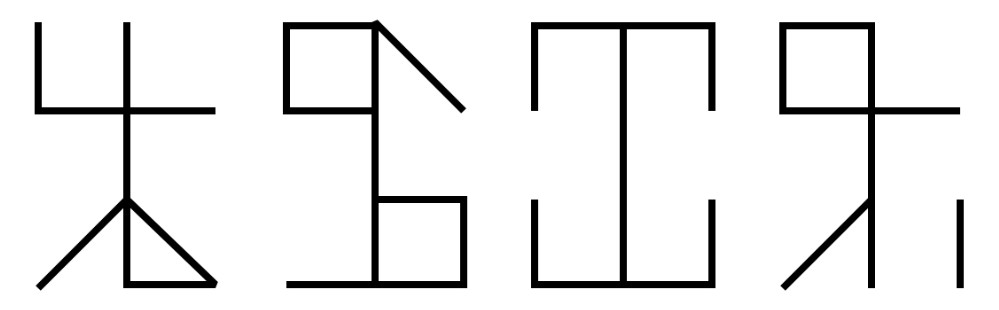
Dans l’ensemble, même si l’on ne connait pas la signification de ces signes, on peut néanmoins inférer un sens caché, la forme étant trop précise pour être due au simple hasard ou à une erreur. D’où certaines interprétations ésotériques, et autres fonctions plus ou moins « secrètes » connues des seuls moines. De fait, King utilise le terme cipher, littéralement le code (dans un sens cryptographique). De là à en faire tout un thriller au temps des moines copistes, il n’y a qu’un pas qu’Umberto Eco ne renierait pas. Formellement, l’aspect global du système – et surtout lorsqu’il utilise des barres obliques – peut faire penser à de l’écriture runique. Ces deux systèmes n’ont toutefois pas une origine commune.
Variantes
On peut distinguer dans ce système deux variantes majeures, caractérisées par l’orientation du fût principal, en gardant toutefois à l’esprit que le système était en réalité plus varié que ce qui va être montré ci-après en ce qui concerne les détails de notation des valeurs numériques.
En Grande Bretagne il est vertical, le sens de lecture se fait de manière différente par rapport à notre mode de lecture habituel (de haut en bas et de gauche à droite), puisque les milliers sont situés en bas à gauche, les centaines en bas à droite, les dizaines en haut à gauche et enfin les unités en haut à droite, on lit donc de gauche à droite, mais de bas en haut. Toutes les valeurs numériques sont notées avec des segments simples ou composés, avec des composants parfois horizontaux, parfois verticaux et parfois obliques.
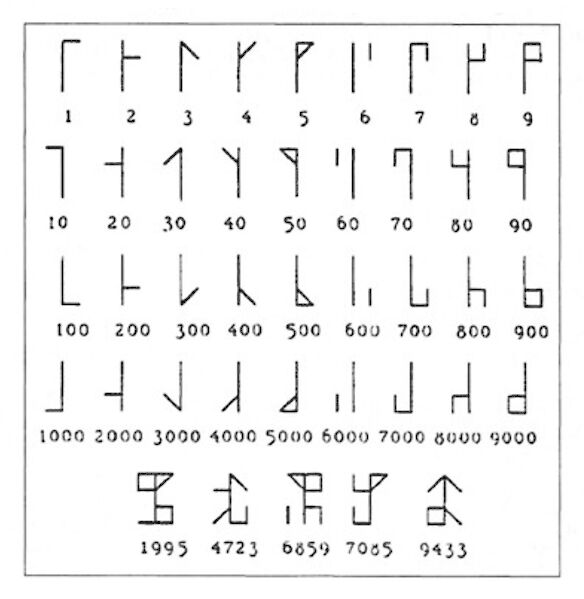
En actuelle France et Belgique, une forme horizontale semble privilégiée, tout en gardant les mêmes méthodes de construction. On note toutefois l’introduction de point ou de cercles en lieu et place des barres pour la valeur [5] voire [6]. Cette forme aurait en particulier été utilisée dans des index de manuscrit, où sa forme compacte était avantageuse, et ce malgré l’utilisation dans le même ouvrage des systèmes romain et indo-arabe.
Critique du travail de King
Comme expliqué précédemment, le corpus à étudier montrant l’utilisation de cette notation est très limité : 25 manuscrits datés entre le XIIIe et le XVIe, plus des textes et mentions poussant jusqu’au tout début du XIXe siècle. C’est probablement la finesse de ce corpus qui a justement poussé David A. King à faire ce travail de recherche, faisant de lui un pionnier de la recherche dans ce domaine. Force est de constater que je n’ai pu trouver d’autres recherches scientifiques sur le sujet qui auraient pu compléter, s’opposer ou confirmer de manière claire les propos de King. N’ayant pas pu me procurer l’ouvrage, je ne peux pas prétendre à une analyse exhaustive. Je n’ai de toute façon pas le bagage scientifique adéquat pour en juger. Je me base donc ici sur des travaux d’autres personnes. Plusieurs sources (publiées dans des revues notamment) font néanmoins un retour sur l’ensemble de son ouvrage et semblent au moins confirmer la qualité de sa méthodologie et par extension de la solidité de ses résultats au vu du corpus étudié. Quelques erreurs de chronologie ou de renvois ont toutefois été repérées. Si des critiques peuvent se faire jour dans le futur, le travail de David A. King est au moins admis comme une base de recherche solide pour des études ultérieures.
En somme ce système fut une sorte de parenthèse très spécifique dans l’histoire de la notation des nombres, presque une anecdote, mais c’est justement ce qui en fait son charme.
Si vous voulez générer les signes à partir de chiffres indo-arabes, j'ai développé un petit outil disponbile en ligne à cette adresse.
- The Ciphers of the Monks – A forgotten Number-Notation of the Middle Ages, David A. King, Franz Steiner Verlag, 2001 (source)
- Système cistercien de notation numérique, Wikipedia (source)
- « David A. King , The Ciphers of the Monks. A forgotten Number-Notation of the Middle Ages », Alain Boureau, Histoire & mesure XVIII 1/2, pp.199-201, 2003 (source)
- « David A. King, The Ciphers of the Monks: A forgotten Number-Notation of the Middle Ages » [compte-rendu], Revue d’histoire des sciences, 58-1, pp. 253-255, 2004 (source)
- « Wine-Gauging at Damme [The evidence of a late medieval manuscript] », Ad Meskens - Germain Bonte - Jacques de Groot - Mike de Jonghe & David A. King, Histoire & Mesure, 14-1-2, pp. 51-77, 1999 (source)
- « Se mettre à l’heure des moines », Loïc Mangin, pourlascience.fr, 10 octobre 2018 (source)
- « The forgotten Number System », Numberphile (chaine YouTube), 5 nov. 2020 (source YouTube)