Avec un titre pareil, on pourrait croire que l’on se dirige sur l’idée d’une soi-disant forme parfaite de la typographie, aux relents de conservatisme, et bien non. On pourrait également penser qu’il va s’agir de parler d’une culture typographique vernaculaire, propre à une zone géographique et en faire un safari ? Si la chose est intéressante, puisqu’il en existe des exemples, ici, un léger pas de côté va être fait.
Tout en restant légèrement chauvins – puisqu’il s’agira surtout du cas breton – nous allons explorer des voies de création typographique à rebours du verre de cristal : des signes pensés pour refléter une histoire, un patrimoine et une culture locale. En plus, il y a une certaine actualité.
Degemer mat e Breizh
Avec son travail intitulé « La bolée de cristal », Jeanne Saliou, qui a très récemment quitté les bancs de l’ANRT, nous propose un caractère typographique embrassant pleinement la culture bretonne du point de vue du dessin de caractère. En effet, le Gwenhadu (s’il s’agit bien là du nom du caractère, chose dont je ne suis totalement sûr) propose un caractère de labeur intégrant des formes rappelant la traduction calligraphique et typographique de l’espace culturel breton. Cela passe par des formes enluminées des capitales, en forme de clin d’œil, mais aussi, et de façon plus directement palpable, de ‹ G › et de ‹ g › peu habituels pour le commun des mortels. S’ajoutent aussi deux sets stylistiques pour aller plus loin dans la coloration du texte, mais également un ensemble de ligatures et glyphes spécifiques. On trouvera évidemment le fameux ‹ Ꝃ › [K barré], signe abréviatif pour Ker pouvant signifier chez, ville, ou plus généralement un lieu. Finalement, il est assez proche de ‹ & › [esperluette], signe abréviatif pour et, sauf que lui ne s’est pas fait interdire par l’État en 1895, et ne suscite pas particulièrement de tensions, comme le suggère Yann Saliou en 1992. Le breton étant ce qu’il est, son utilisation de l’alphabet latin diffère du français. Ainsi certaines successions de lettres ont permis de proposer des ligatures très spécifiques : ‹ zh ›, ‹ gn ›, ‹ c’h › ; ou plus étonnantes pour une personne ne sachant rien (comme moi-même) du breton : ‹ vM › et ‹ gK ›, avec une minuscule avant une majuscule, oui.
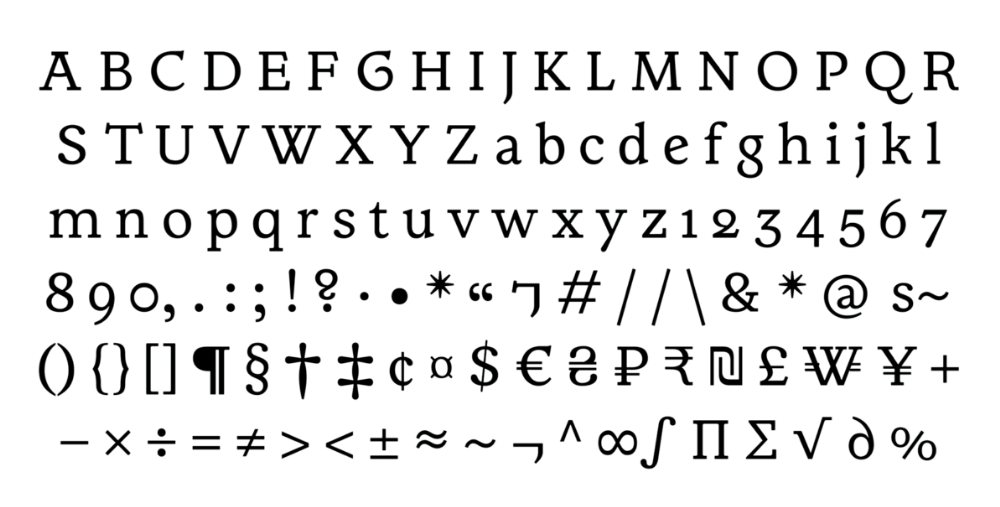

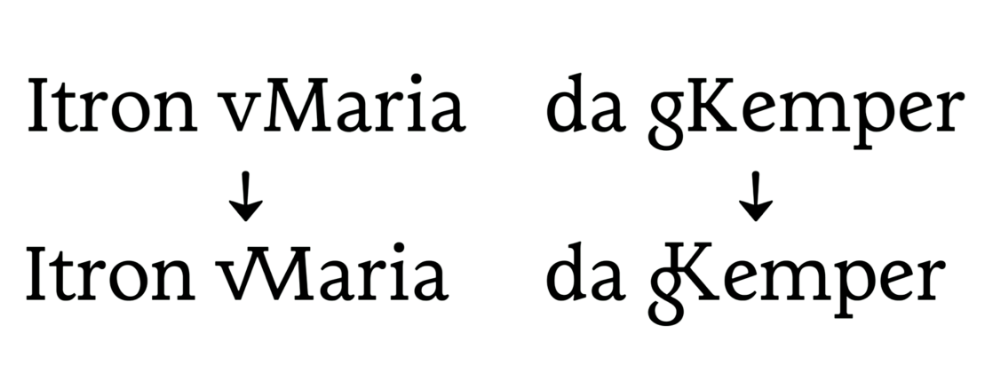
Inscrit dans des problématiques contemporaines, le caractère intègre également un ensemble de ligatures spécifiques à ce qui pourrait devenir un breton inclusif, offrant entre autres des ligatures pour ‹ re ›, ‹ vb ›, ‹ Gc’h › et ‹ c’hg ›. Il semble donc que le breton entre dans une ère contemporaine dont la typographie peut fournir à la fois une identité graphique, et répondre à des enjeux à la fois linguistiques, patrimoniaux et actuels.

Rannvro Breizh
Si le travail de cette designer est le plus récent que je connaisse, ce travail de modélisation typographique de la Bretagne n’est pas nouveau. Pour les Bretons c’est assez familier, pour les autres peut-être moins, mais nous associons déjà la région à une forme typographique : celle de sa communication officielle. Elle utilise un caractère exclusif dessiné par Xavier Dupré à partir de son caractère Spotka, le Région Bretagne, dont les terminaisons de lettres et les capitales spécifiques feront probablement surgir un ding dans votre mémoire.
Au-delà de la commande officielle, on peut évidemment citer Skritur, studio de design graphique et typographique fondé par Fañch Le Henaff, Malou Verlomme et Yoann De Roeck qui « recense, décrypte, interprète et conçoit dans le champ de la chose écrite (inscrite, calligraphique, typographique) en Bretagne particulièrement, mais plus largement les pays celtiques et dans tout lieu où se mêlent les particularismes idiomatiques et les graphies singulières ». La structure propose ainsi des caractères inspirés très directement de la culture bretonne et plus généralement celte donc, que je vous laisserai découvrir, mais également des articles sur le patrimoine graphique et typographique de la région. Pour dire la démarche jusqu’au-boutiste de la structure, rappelons que Yoan De Roeck est en ce moment même en train de mener une recherche doctorale fort à propos : « L’immatriculation des chaloupes en Bretagne (1852–1914) – Approche typographique d’un phénomène d’épigraphie vernaculaire » dirigée par Marc Smith, probablement l’épigraphe français le plus célèbre, et dont la Véridique histoire de l’arobase, publiée récemment, est un must-have pour les curieux des signes.
Nos régions ont du talent (graphique)
Le cas breton est assez significatif des possibilités offertes par la typographie dans la mise en avant d’un patrimoine culturel régional, et évidemment, il y a d’autres exemples à citer maintenant, sans toutefois prétendre à une quelconque exhaustivité.
Pour rester dans la communication publique, évoquons le travail non retenu du studio Graphéine pour un nouveau logo de Biarritz, reprenant des formes de lettres inspirées par la graphie basque, avec notamment le ‹ A › à traverse en pointe et double serif en chef.
Pour le versant typo-linguistique, citons le travail d’Agnès Brézéphin sur le Coolie, avec des ligatures pour le parler créole ; le Pitchoune de Yann Linguinou pour le parler marseillais ; le Traulha, issu du projet de diplôme de Yoann Minet qui s’intéressait quant à lui à la culture occitane ; la proposition de ligature ‹ hj › spécifique au corse de Xavier Dandoy ; et enfin le Munegascu de Bruno Bernard – basé sur l’Archivo – qui intègre des diacritiques (des accents) spécifiques au monégasque. Pour terminer avec ces exemples, n’oublions pas la fiction et le Bubunne de Fanette Mellier, pensé pour le film Jacky au royaume des filles de Riad Sattouf, où l’on constate qu’une dystopie fascho-communo-féministe (oui, je vous laisse avec ça) a bien besoin d’une forme typographique adéquate.

Entre le verre de cristal – le texte invisible – et la bolée – le texte culturellement et géographiquement ancré – l’éventail des formes typographiques est grand. Les possibilités techniques actuelles avec les sets stylistiques et les ligatures/ligatures conditionnelles facilitent ce type de créations. Il faudrait néanmoins que l’encodage typographique suive. Si c’est le cas pour le ‹ Ꝃ › et le ‹ ꝃ › depuis 2008 avec Unicode 5.1.0, qu’en est-il d’autres formes typographiques régionales, voire nationales ?
Spoiler alert : il y a encore du travail.
- Jeanne Saliou, « La bolée de cristal – dessiner un caractère adapté à la lecture longue en breton », ANRT, 03/2025, 35 min (source)
- Xavier Dupré, « Région Bretagne » (source)
- Région Bretagne, « Charte graphique Région Bretagne – édition 2016 », 2016 (source PDF)
- Yann Riou, « Le k barré d’hier à aujourd’hui », association Lambaol, 1992 (source PDF)
- Julien Marchand, « Le k barré : la lettre interdite », Bikini, 63, 09-10/2023, p. 26-31 (source)
- Skritur, « Our project » (source)
- Yoan De Roeck, « L’immatriculation des chaloupes en Bretagne (1852-1914) – Approche typographique d’un phénomène d’épigraphie vernaculaire », theses.fr, depuis 2021 (source)
- Marc H. Smith, La véridique histoire de l’arobase, « Propos », École des chartes éditions, 2024 (source)
- Graphéine, « Projet d’identité visuelle pour la Ville de Biarritz », 06/04/2023 (source)
- Yann Linguinou, « Pitchoune » (source)
- Xavier Dandoy, « Recherches typographiques » (source)
- Bruno Bernard, « Munegascu, une typographie pour écrire la langue monégasque », 23/11/2024 (source)
- compart.com, « Unicode Character “Ꝃ” (U+A742) » & « Unicode Character “ꝃ” (U+A743) », (source & source)